Introduction
The KoLeo loss is a regularizer that pushes representations to spread uniformly in their space by maximizing their minimum distance from each other.
It was introduced in this paper. It is a loss function derived from the Kozachenko–Leonenko estimator. It allows approximating Shannon entropy using distances to the k nearest neighbors. If you want to learn more about this estimator, I recommend visiting this page.
The DINO family of self-supervised learning models has implemented this loss which you can find here.
The KoLeo loss is defined as follows
$$ \mathcal{L}_{KoLeo} = - \frac{1}{n} \sum_{i=1}^n \log\left( \min_{j \ne i} | f(x_i) - f(x_j) | \right) $$
where \(n\) is the batch size. For each embedding in the batch, the loss computes the logarithm of its minimum distance to all other embeddings in the same batch. The negative sign ensures that maximizing the minimum distance corresponds to minimizing the loss, encouraging embeddings to spread out in the representation space.
So the total loss becomes
$$ \mathcal{L} = \mathcal{L}_{triplet} + \lambda\mathcal{L}_{KoLeo} $$
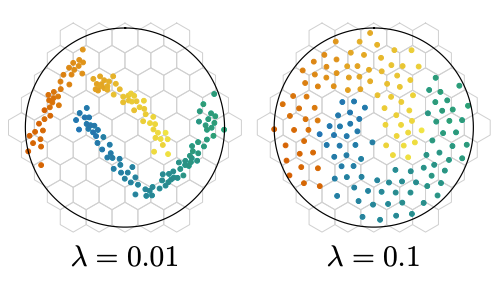
One of the key benefits of this loss is preventing collapse. Model collapse refers to a failure mode in self-supervised learning where the model learns to map all inputs to the same (or very similar) embedding vector. When collapse occurs, all the learned features are indistinguishable and the model loses its ability to represent meaningful differences between examples, effectively destroying the utility of the learned representations. The KoLeo loss mitigates this by encouraging the embeddings to spread out in the representation space, helping the model avoid this degenerate solution. Here an illustration that comes from the paper:
We will therefore try to integrate the KoLeo loss into our training code and observe the results on our siamese network. Will we observe, as expected, a greater spread of embeddings?
Integrating the KoLeo loss into the code
First, let’s take the KoLeo loss implementation from DINOv2.
import torch
import torch.nn as nn
import torch.nn.functional as F
torch.use_deterministic_algorithms(True)
class KoLeoLoss(nn.Module):
"""Kozachenko-Leonenko entropic loss regularizer from Sablayrolles et al. - 2018 - Spreading vectors for similarity search"""
def __init__(self):
super().__init__()
self.pdist = nn.PairwiseDistance(2, eps=0)
def pairwise_NNs_inner(self, x):
"""
Pairwise nearest neighbors for L2-normalized vectors.
Uses Torch rather than Faiss to remain on GPU.
"""
# parwise dot products (= inverse distance)
dots = torch.mm(x, x.t())
n = x.shape[0]
dots.view(-1)[:: (n + 1)].fill_(-1) # Trick to fill diagonal with -1
_, indices = torch.max(dots, dim=1) # max inner prod -> min distance
return indices
def forward(self, student_output, eps=1e-8):
"""
Args:
student_output (BxD): backbone output of student
"""
student_output = F.normalize(student_output, eps=eps, p=2, dim=-1)
indices = self.pairwise_NNs_inner(student_output)
distances = self.pdist(student_output, student_output[indices]) # BxD, BxD -> B
loss = -torch.log(distances + eps).mean()
return loss
To avoid rewriting several utility functions (such as data loading, triplet building, and training helpers) directly in the notebook, I have put them in a separate Python file called training_utils.py. This allows us to keep the notebook concise and focused on the experimental logic, while reusing these helper functions as needed. Later, we will also have a separate plot_utils.py for plotting utilities. All training code and utilities can be found in this repository
import sys
sys.path.append("../..")
from training_utils import (
get_device, load_cifar10, build_triplets,
create_datasets, VGG11Embedding, triplet_loss,
setup_training_dir, log_metrics, print_metrics,
plot_losses, construct_embeddings_by_class, LABEL_NAMES
)
Training
As in part 1, we start by defining the seed and building our triplets.
For the sake of reproducibility, I set the device to CPU here. As I am on a Mac, I would normally use ‘mps’, but the KoLeo loss produces slight differences between same runs on ‘mps’ for unclear reasons. This requires further investigation, so I will keep everything on CPU for this first run. Later, when using k-fold, we will switch to ‘mps’, sacrificing reproducibility for speed.
import numpy as np
seed = 42
device = get_device()
device = "cpu"
print(f"Device: {device}")
images, labels = load_cifar10("../cifar-10-python")
print(f"Images shape: {images.shape}, Labels shape: {labels.shape}")
np.random.seed(seed)
triplets, triplets_labels = build_triplets(images, labels, n_neg=2500, seed=seed)
print(f"Triplets shape: {triplets.shape}")
> Images shape: (50000, 32, 32, 3), Labels shape: (50000,)
> Triplets shape: (25000, 3, 32, 32, 3)
Here we add the koleo_weight variable, our \(\lambda\) parameter of the total loss formula.
batch_size = 64
learning_rate = 5e-4
margin = 0.4
koleo_weight = 0.1
val_split = 0.05
train_dataset, val_dataset, val_triplets, val_labels = create_datasets(triplets, triplets_labels, val_split=val_split, seed=seed)
koleo_loss_fn = KoLeoLoss()
print(f"Train: {len(train_dataset)}, Val: {len(val_dataset)}")
And we rewrite our training loop by inserting the KoLeo loss into the loss calculation.
from sklearn.metrics import roc_auc_score
from tqdm import tqdm
def train_loop(net, dataloader, optimizer, margin, koleo_weight, print_freq=100):
net.train()
loss_accum = 0.0
epoch_loss = 0.0
for batch_idx, (anc, pos, neg) in tqdm(enumerate(dataloader)):
anc, pos, neg = anc.to(device), pos.to(device), neg.to(device)
anc_feat, pos_feat, neg_feat = net(anc), net(pos), net(neg)
t_loss = triplet_loss(anc_feat, pos_feat, neg_feat, margin)
all_embeddings = torch.cat([anc_feat, pos_feat, neg_feat], dim=0)
k_loss = koleo_loss_fn(all_embeddings)
if koleo_weight is not None:
loss = t_loss + koleo_weight * k_loss
else:
loss = t_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_accum += loss.item()
epoch_loss += loss.item()
if (batch_idx + 1) % print_freq == 0:
print(f"Batch {batch_idx+1}: Loss = {loss_accum / print_freq:.4f}")
loss_accum = 0.0
return epoch_loss / (batch_idx + 1)
def validation_loop(net, dataloader, margin, koleo_weight, device):
net.eval()
val_loss = 0
total_simple_loss = 0
good_triplets = 0
total_triplets = 0
positive_similarities = []
negative_similarities = []
positive_euclidean_distances = []
negative_euclidean_distances = []
with torch.no_grad():
for batch_idx, (anc, pos, neg) in enumerate(dataloader):
anc, pos, neg = anc.to(device), pos.to(device), neg.to(device)
anc_feat, pos_feat, neg_feat = net(anc), net(pos), net(neg)
simple_loss = triplet_loss(anc_feat, pos_feat, neg_feat, margin)
if koleo_weight is not None:
loss = simple_loss + koleo_weight * koleo_loss_fn(torch.cat([anc_feat, pos_feat, neg_feat], dim=0))
else:
loss = simple_loss
val_loss += loss.item()
total_simple_loss += simple_loss.item()
batch_positive_euclidean_distances = F.pairwise_distance(anc_feat, pos_feat, p=2)
batch_negative_euclidean_distances = F.pairwise_distance(anc_feat, neg_feat, p=2)
positive_euclidean_distances.append(batch_positive_euclidean_distances)
negative_euclidean_distances.append(batch_negative_euclidean_distances)
batch_positive_similarities = F.cosine_similarity(anc_feat, pos_feat, dim=1)
batch_negative_similarities = F.cosine_similarity(anc_feat, neg_feat, dim=1)
positive_similarities.append(batch_positive_similarities)
negative_similarities.append(batch_negative_similarities)
good_triplets += (batch_positive_similarities > batch_negative_similarities).sum()
total_triplets += anc.shape[0]
positive_euclidean_distances = torch.cat(positive_euclidean_distances, dim=0)
negative_euclidean_distances = torch.cat(negative_euclidean_distances, dim=0)
positive_similarities = torch.cat(positive_similarities, dim=0)
negative_similarities = torch.cat(negative_similarities, dim=0)
predict_similarities = torch.cat([positive_similarities, negative_similarities], dim=0)
target_similarities = torch.cat([torch.ones_like(positive_similarities), torch.zeros_like(negative_similarities)], dim=0)
val_auc = roc_auc_score(target_similarities.detach().cpu().numpy(), predict_similarities.detach().cpu().numpy())
mean_positive_similarities = predict_similarities[:len(predict_similarities)//2].mean().item()
mean_negative_similarities = predict_similarities[len(predict_similarities)//2:].mean().item()
mean_positive_euclidean_distances = positive_euclidean_distances.mean().item()
mean_negative_euclidean_distances = negative_euclidean_distances.mean().item()
good_triplets_ratio = (good_triplets / total_triplets).item()
return {
'val_loss': val_loss / (batch_idx + 1),
'simple_loss': total_simple_loss / (batch_idx + 1),
'val_auc': val_auc,
'mean_positive_similarities': mean_positive_similarities,
'mean_negative_similarities': mean_negative_similarities,
'mean_positive_euclidean_distances': mean_positive_euclidean_distances,
'mean_negative_euclidean_distances': mean_negative_euclidean_distances,
'good_triplets_ratio': good_triplets_ratio
}
We then configure our directory where runs will be stored before training.
epochs = 15
config = {
"seed": seed, "batch_size": batch_size, "learning_rate": learning_rate,
"epochs": epochs, "margin": margin, "koleo_weight": koleo_weight, "val_split": val_split
}
save_dir, metrics_path, csv_headers = setup_training_dir("runs_koleo", config)
We can launch the training!
Note that by controlling the random seeds, we ensure that this training run precisely matches the procedure from Chapter 1 in all aspects: model weight initialization, the order of training batches, and image transformations. The only intentional difference in this experiment is the inclusion of the KoLeo loss component. This allows us to perform a fair and direct comparison between the two approaches.
import random
from torch.utils.data import DataLoader
from torchvision.models import VGG11_Weights
train_losses = []
val_losses = []
best_auc = 0
best_epoch_path = None
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
if torch.mps.is_available():
torch.mps.manual_seed(seed)
gt = torch.Generator()
gt.manual_seed(seed)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, generator=gt)
net = VGG11Embedding(weights=VGG11_Weights.IMAGENET1K_V1).to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=learning_rate)
val_metrics = validation_loop(net, val_loader, margin, koleo_weight, device)
print(f"Before training")
print_metrics(val_metrics)
log_metrics(metrics_path, csv_headers, 0, "", val_metrics)
for epoch_idx in range(epochs):
train_loss = train_loop(net, train_loader, optimizer, margin, koleo_weight)
val_metrics = validation_loop(net, val_loader, margin, koleo_weight, device)
val_losses.append(val_metrics['val_loss'])
train_losses.append(train_loss)
print(f"Epoch {epoch_idx+1} - train_loss: {train_loss:.4f}, val_loss: {val_metrics['val_loss']:.4f}, val_auc: {val_metrics['val_auc']:.4f}")
print_metrics(val_metrics)
log_metrics(metrics_path, csv_headers, epoch_idx + 1, train_loss, val_metrics)
if val_metrics['val_auc'] > best_auc:
best_auc = val_metrics['val_auc']
if best_epoch_path is not None:
best_epoch_path.unlink()
best_epoch_path = save_dir / f'best_epoch_{epoch_idx+1}.pth'
torch.save(net.state_dict(), best_epoch_path)
print(f"New best AUC: {best_auc:.4f} at epoch {epoch_idx+1}")
Validation metrics — val_loss: 0.3296, simple_loss: 0.3156, val_auc: 0.6642, mean_positive_similarities: 0.2750, mean_negative_similarities: 0.1853, mean_positive_euclidean_distances: 1.1968, mean_negative_euclidean_distances: 1.2714, good_triplets_ratio: 0.6656
100it [01:57, 1.14s/it]
Batch 100: Loss = 0.2912
200it [03:57, 1.14s/it]
Batch 200: Loss = 0.2490
300it [05:55, 1.19s/it]
Batch 300: Loss = 0.2377
372it [07:17, 1.18s/it]
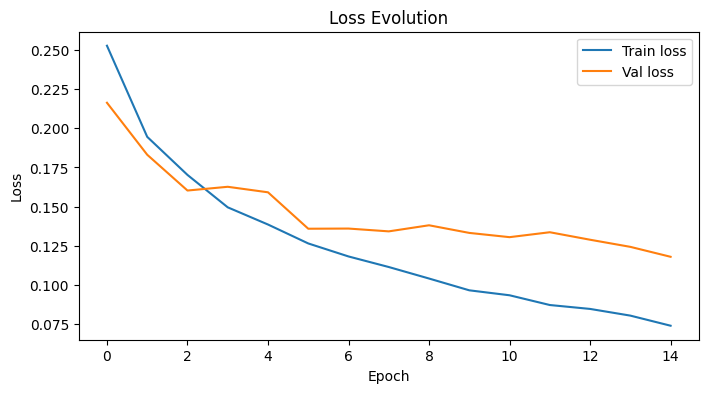
Epoch 1 - train_loss: 0.2526, val_loss: 0.2162, val_auc: 0.8592
Validation metrics — val_loss: 0.2162, simple_loss: 0.1416, val_auc: 0.8592, mean_positive_similarities: 0.5595, mean_negative_similarities: 0.1074, mean_positive_euclidean_distances: 0.8938, mean_negative_euclidean_distances: 1.3127, good_triplets_ratio: 0.8616
New best AUC: 0.8592 at epoch 1
...
Epoch 15 - train_loss: 0.0741, val_loss: 0.1180, val_auc: 0.9433
Validation metrics — val_loss: 0.1180, simple_loss: 0.0800, val_auc: 0.9433, mean_positive_similarities: 0.4785, mean_negative_similarities: -0.0332, mean_positive_euclidean_distances: 1.0030, mean_negative_euclidean_distances: 1.4291, good_triplets_ratio: 0.9368
New best AUC: 0.9433 at epoch 15
plot_losses(train_losses, val_losses, title="Loss Evolution")
Loading of the best model.
best_epoch_path = list((save_dir.glob('best_epoch_*.pth')))[0]
net.load_state_dict(torch.load(best_epoch_path))
Results
Distance Matrix
Let’s now visualize the distance matrix of embeddings and compare it to the distance matrix obtained in chapter 1. As with the training_utils.py file, I also created the plot_utils.py file.
from plot_utils import compute_distance_matrix, plot_distance_matrix_heatmap
from training_utils import VAL_TRANSFORMS
embeddings_by_class = construct_embeddings_by_class(net, val_labels, val_triplets, VAL_TRANSFORMS, device)
dist_matrix = compute_distance_matrix(embeddings_by_class)
plot_distance_matrix_heatmap(dist_matrix, LABEL_NAMES, save_dir / "distance_matrix_heatmap.png")
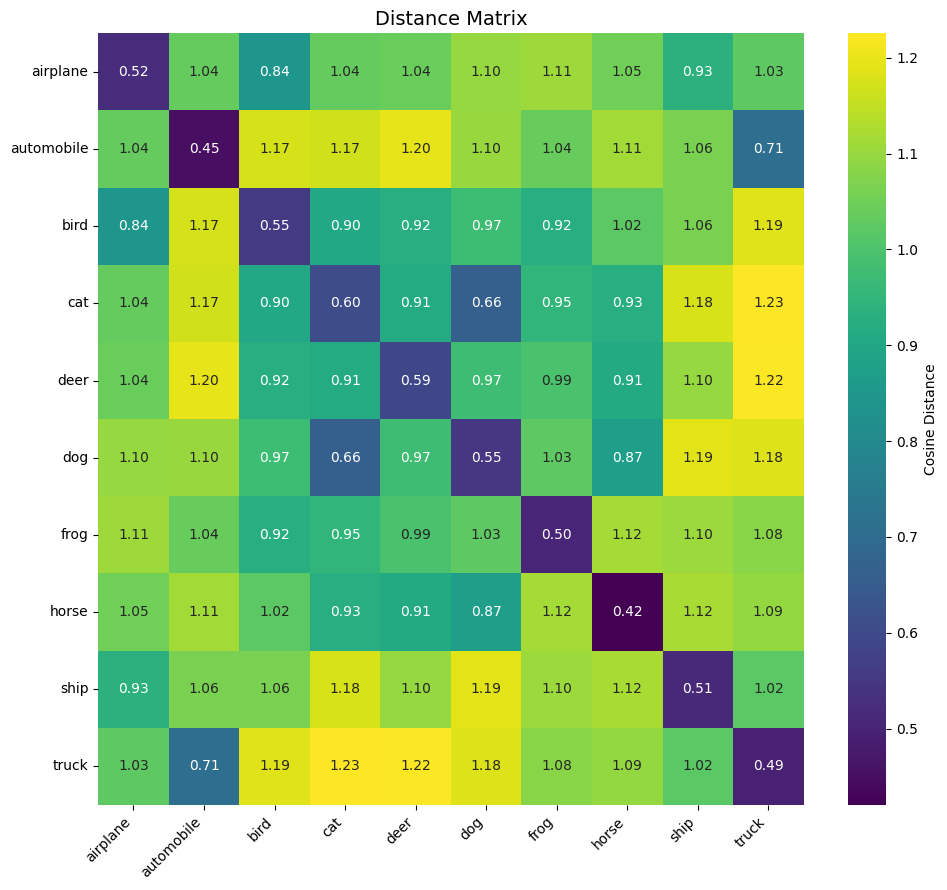
> Inter-class distance: mean=1.0350, std=0.1244
> Separation margin: 0.5147
Let’s display the matrix obtained without the KoLeo loss.
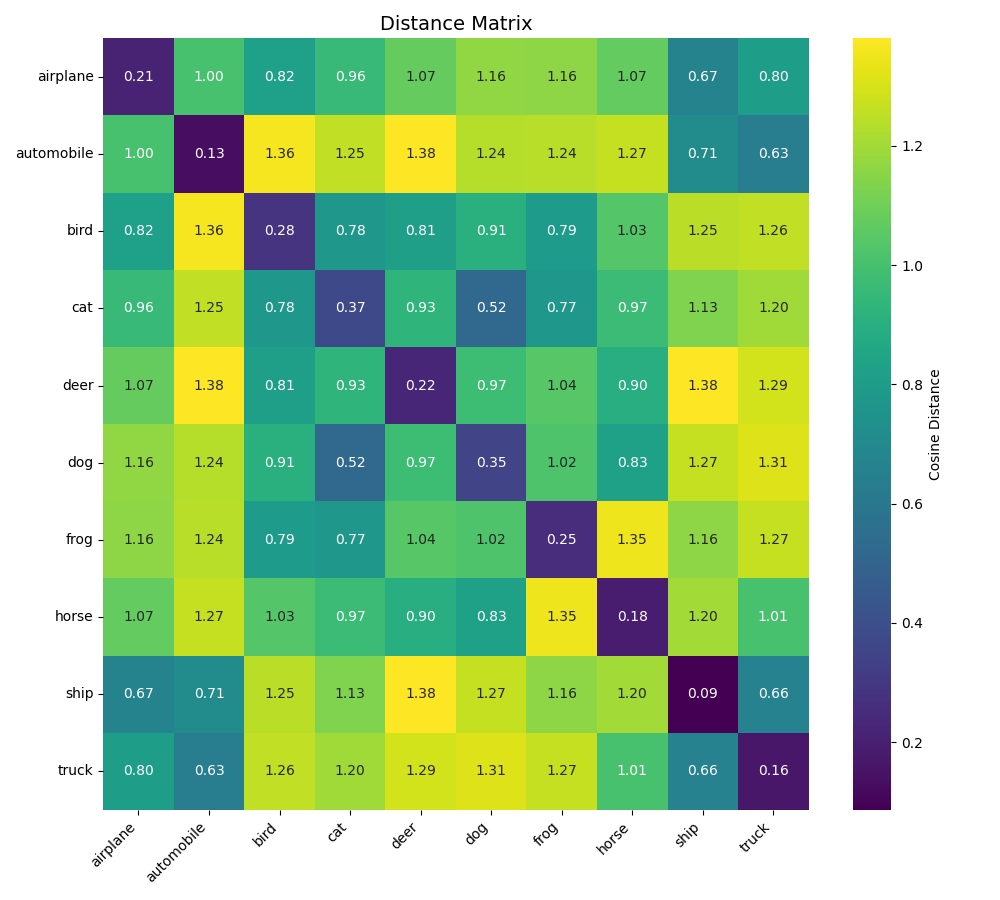
We can already observe that the distance values in the diagonals are lower when the model was trained with the simple triplet loss. This seems to indicate that the data is more spread out in their space.
| Metric | Without KoLeo | With KoLeo |
|---|---|---|
| Intra-class distance | mean=0.2249, std=0.0865 | mean=0.5202, std=0.0545 |
| Inter-class distance | mean=1.0392, std=0.2285 | mean=1.0350, std=0.1244 |
| Separation margin | 0.8143 | 0.5147 |
The comparison reveals that the KoLeo loss significantly increases intra-class distances (more than doubled from 0.2249 to 0.5202), confirming the greater spread of embeddings within each class. The inter-class distances remain similar (1.0392 vs 1.0350), while the separation margin decreases from 0.8143 to 0.5147, reflecting the trade-off between intra-class spread and inter-class separation.
Let’s see what this looks like on a plane using PCA. We’ll display the normalized version right away to compare with the previous projection.
import numpy as np
from sklearn.decomposition import PCA
from plot_utils import get_ellipse_params_per_class, plot_embeddings_with_ellipses
all_embeddings = torch.cat([embeddings_by_class[k] for k in embeddings_by_class], dim=0)
pca_2d = PCA(n_components=2)
embeddings_2d = pca_2d.fit_transform(all_embeddings)
embeddings_2d = (embeddings_2d - embeddings_2d.min(axis=0)) / (embeddings_2d.max(axis=0) - embeddings_2d.min(axis=0))
samples_per_class = [len(embeddings_by_class[i]) for i in range(10)]
labels_array = np.concatenate([np.full(count, label) for label, count in enumerate(samples_per_class)])
ellipse_params = get_ellipse_params_per_class(embeddings_2d, labels_array, LABEL_NAMES, coverage=0.5)
plot_embeddings_with_ellipses(
embeddings_2d,
ellipse_params,
labels_array,
LABEL_NAMES,
save_img_path = save_dir / "embeddings_2d_normalized.png",
)
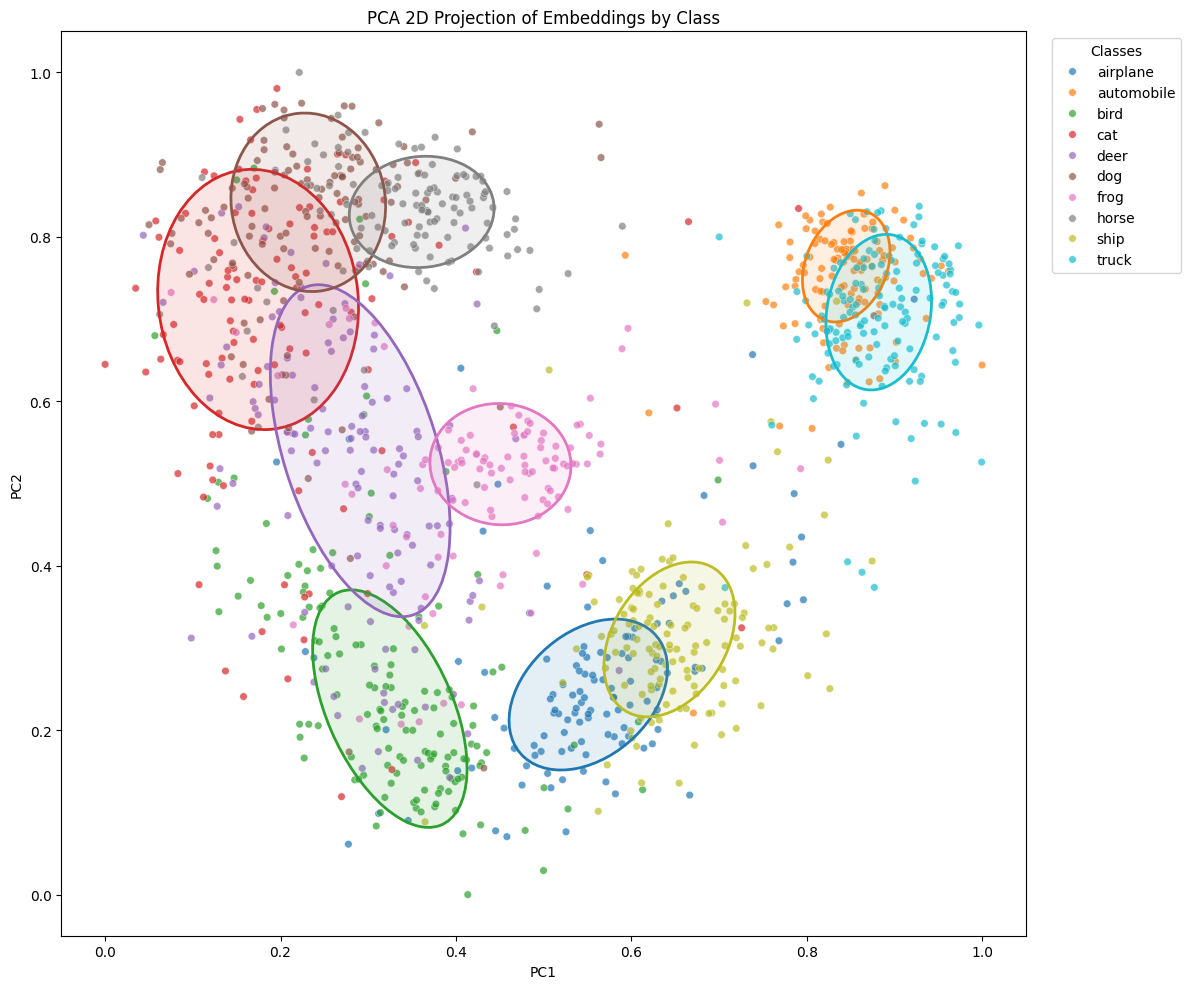
Let’s recall the projection without the KoLeo loss
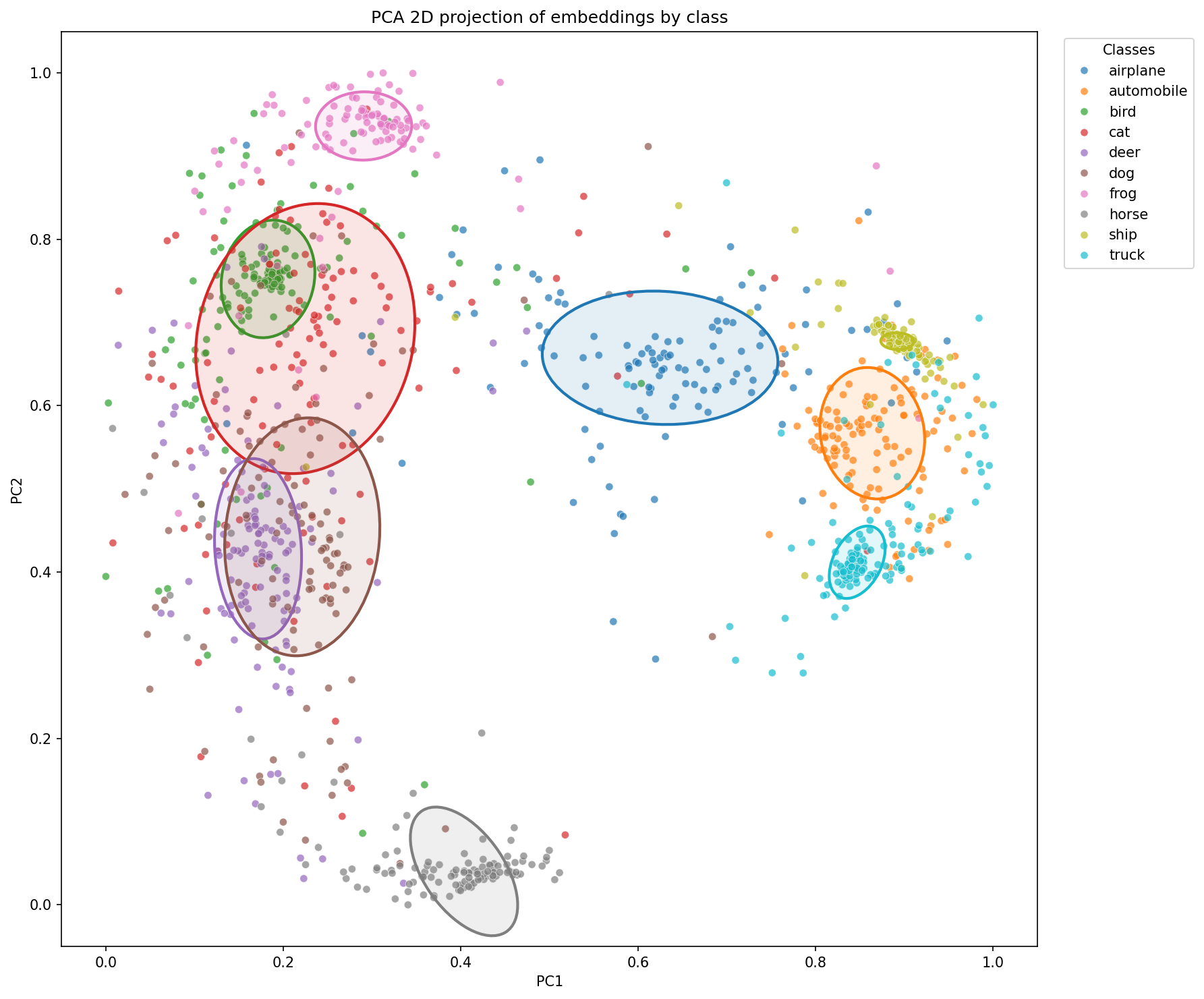
We observe that the KoLeo loss seems to indeed spread the embeddings more in space. The ellipses appear globally larger, which is consistent with the regularization objective: maximizing the minimum distance between representations.
To quantify this observation, let’s calculate the areas of the ellipses for a few representative classes.
for k, v in ellipse_params.items():
area = np.pi * v["width"] * v["height"]
v["area"] = area
print("Ellipse areas (with KoLeo loss):")
for k in ["cat", "dog", "horse", "ship"]:
print(f" Area of {k}'s ellipse = {ellipse_params[k]['area']:.6f}")
> Area of cat's ellipse = 0.227323
> Area of dog's ellipse = 0.120206
> Area of horse's ellipse = 0.070161
> Area of ship's ellipse = 0.083406
Let’s compare these values with those obtained without the KoLeo loss:
| Class | Without KoLeo | With KoLeo |
|---|---|---|
| cat | 0.0626 | 0.2273 |
| dog | 0.0392 | 0.1202 |
| horse | 0.0125 | 0.0702 |
| ship | 0.0006 | 0.0834 |
The ellipse areas confirm this observation: all classes show larger ellipse areas when trained with the KoLeo loss, indicating a greater spread of embeddings in the representation space.
Results vary from one run to another depending on the seed and train/validation split. To have a more robust and statistically significant comparison, we will use k-fold cross-validation.
K-Fold implementation
We will use KFold from scikit-learn to divide our triplets into K=5 folds.
K-fold cross-validation is a technique used to assess how a machine learning model generalizes to an independent dataset. The data is split into K approximately equal subsets (“folds”). For each of K iterations, one fold is held out as the validation set, and the model is trained on the remaining K-1 folds. This process allows each data point to be used for both training and validation, providing a more robust estimate of model performance.
Here an illustration of KFold when k=5.
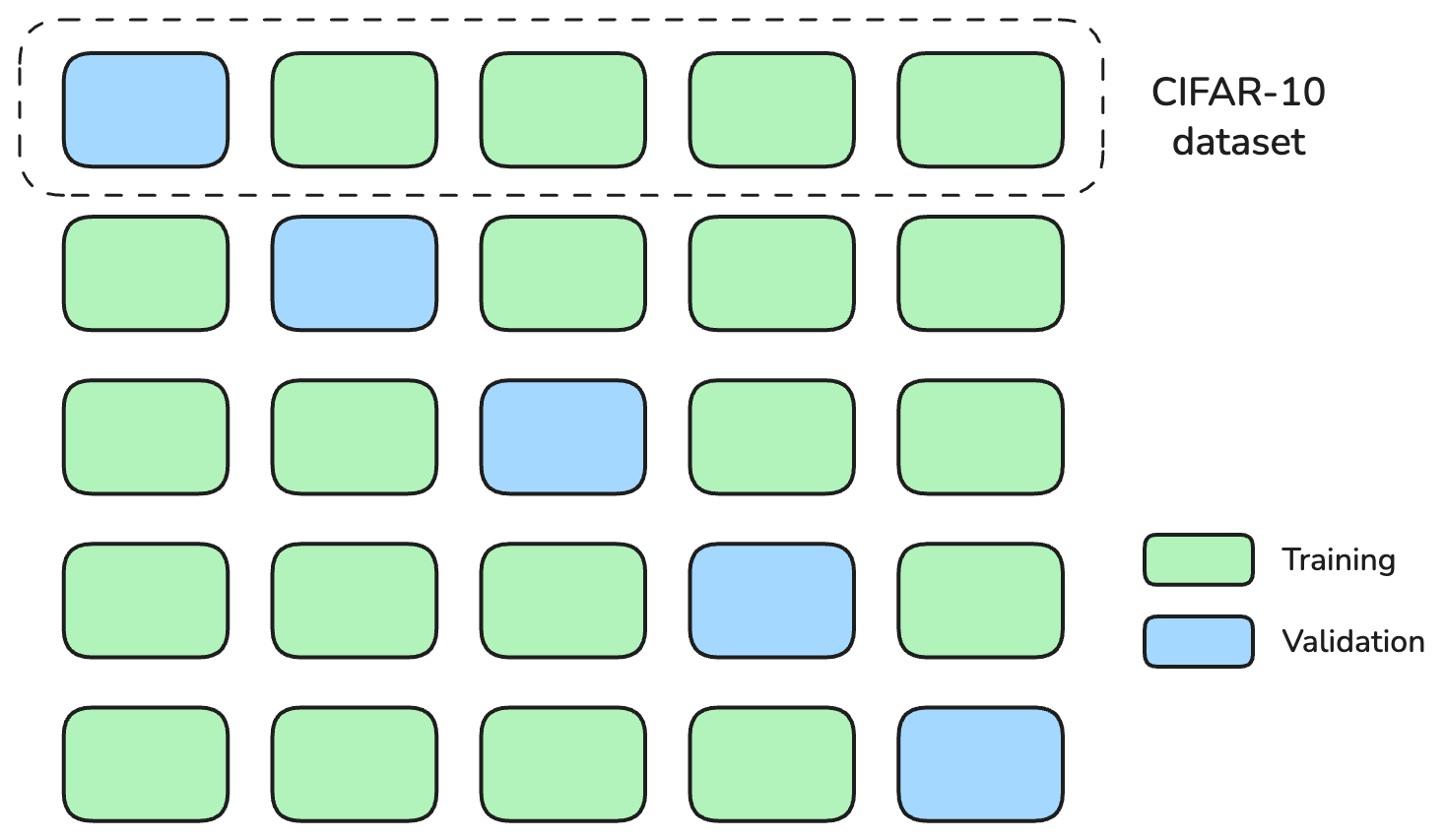
For each fold, we will train two models: one with triplet loss alone, and one with triplet loss + KoLeo loss. We will then collect the ellipse areas for each class.
To keep the computation time reasonable
- we switch to mps device like said at the beggining of this article
- we reduce the number of training epochs per fold, since running many epochs for each model and fold would take too long.
from sklearn.model_selection import KFold
import copy
K_FOLDS = 5
EPOCHS_PER_FOLD = 7
kfold = KFold(n_splits=K_FOLDS, shuffle=True, random_state=seed)
device = get_device()
results_no_koleo = {"areas": {cls: [] for cls in LABEL_NAMES}, "auc": []}
results_with_koleo = {"areas": {cls: [] for cls in LABEL_NAMES}, "auc": []}
We define a function that trains a model and returns the ellipse areas. We will also ensure that the training loader always returns the same data for both trainings by initializing the seed just before the training loop. We also add more data for the final experiment.
from torch.utils.data import DataLoader
from torchvision.models import VGG11_Weights
from tqdm import tqdm
from training_utils import TripletsCIFAR10Dataset, TRAIN_TRANSFORMS
def train_and_compute_metrics(train_triplets, val_triplets, val_labels, use_koleo, epochs=2):
train_dataset = TripletsCIFAR10Dataset(train_triplets, transform=TRAIN_TRANSFORMS)
val_dataset = TripletsCIFAR10Dataset(val_triplets, transform=VAL_TRANSFORMS)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
model = VGG11Embedding(weights=VGG11_Weights.IMAGENET1K_V1).to(device)
optim = torch.optim.Adam(model.parameters(), lr=learning_rate)
kw = koleo_weight if use_koleo else 0.0
best_auc = 0.0
best_model_state = None
torch.manual_seed(seed)
for epoch in tqdm(range(epochs)):
model.train()
for anc, pos, neg in train_loader:
anc, pos, neg = anc.to(device), pos.to(device), neg.to(device)
anc_feat, pos_feat, neg_feat = model(anc), model(pos), model(neg)
loss = triplet_loss(anc_feat, pos_feat, neg_feat, margin)
if use_koleo:
all_emb = torch.cat([anc_feat, pos_feat, neg_feat], dim=0)
loss += kw * koleo_loss_fn(all_emb)
optim.zero_grad()
loss.backward()
optim.step()
val_metrics = validation_loop(model, val_loader, margin, kw if use_koleo else None, device)
current_auc = val_metrics['val_auc']
if current_auc > best_auc:
best_auc = current_auc
best_model_state = copy.deepcopy(model.state_dict())
model.load_state_dict(best_model_state)
embeddings_by_class = construct_embeddings_by_class(model, val_labels, val_triplets, VAL_TRANSFORMS, device)
all_emb = torch.cat([embeddings_by_class[k] for k in embeddings_by_class], dim=0)
dist_matrix = compute_distance_matrix(embeddings_by_class)
pca = PCA(n_components=2)
emb_2d = pca.fit_transform(all_emb)
emb_2d = (emb_2d - emb_2d.min(axis=0)) / (emb_2d.max(axis=0) - emb_2d.min(axis=0))
samples = [len(embeddings_by_class[i]) for i in range(10)]
lab_arr = np.concatenate([np.full(c, l) for l, c in enumerate(samples)])
ellipse_p = get_ellipse_params_per_class(emb_2d, lab_arr, LABEL_NAMES, coverage=0.5)
areas = {}
for cls in LABEL_NAMES:
areas[cls] = np.pi * ellipse_p[cls]["width"] * ellipse_p[cls]["height"]
return {
"areas": areas,
"auc": best_auc,
"embeddings_by_class": embeddings_by_class,
"dist_matrix": dist_matrix,
"emb_2d": emb_2d,
"lab_arr": lab_arr,
"ellipse_params": ellipse_p
}
Training
Let’s now launch the cross-validation. Note: this cell may take several minutes to execute (K folds × 2 models × epochs) = 5 x 2 x 7 = 10 trainings of 7 epochs each = 70 epochs.
for fold_idx, (train_idx, val_idx) in enumerate(kfold.split(triplets)):
print(f"\n{'='*50}")
print(f"Fold {fold_idx + 1}/{K_FOLDS}")
print(f"{'='*50}")
fold_train_triplets = triplets[train_idx]
fold_val_triplets = triplets[val_idx]
fold_train_labels = triplets_labels[train_idx]
fold_val_labels = triplets_labels[val_idx]
print(f"Training WITHOUT KoLeo loss...")
metrics_no_koleo = train_and_compute_metrics(
fold_train_triplets,
fold_val_triplets, fold_val_labels,
use_koleo=False, epochs=EPOCHS_PER_FOLD
)
for cls in LABEL_NAMES:
results_no_koleo["areas"][cls].append(metrics_no_koleo["areas"][cls])
results_no_koleo["auc"].append(metrics_no_koleo["auc"])
print(f" Best AUC: {metrics_no_koleo['auc']:.4f}")
print(f"Training WITH KoLeo loss...")
metrics_with_koleo = train_and_compute_metrics(
fold_train_triplets,
fold_val_triplets, fold_val_labels,
use_koleo=True, epochs=EPOCHS_PER_FOLD
)
for cls in LABEL_NAMES:
results_with_koleo["areas"][cls].append(metrics_with_koleo["areas"][cls])
results_with_koleo["auc"].append(metrics_with_koleo["auc"])
print(f" Best AUC: {metrics_with_koleo['auc']:.4f}")
print(f"Fold {fold_idx + 1} done.")
Fold 1/5
==================================================
Training WITHOUT KoLeo loss...
100%| █████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [04:15<00:00, 36.45s/it]
Best AUC: 0.9140
Training WITH KoLeo loss...
100%|█████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [04:12<00:00, 36.08s/it] Best AUC: 0.9186
Fold 1 done.
...
==================================================
Fold 5/5
==================================================
Training WITHOUT KoLeo loss...
100%|█████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [05:00<00:00, 42.88s/it]
Best AUC: 0.9300
Training WITH KoLeo loss...
100%|█████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [05:10<00:00, 44.36s/it]
Best AUC: 0.9217
Fold 5 done.
Results
auc_no_koleo = np.array(results_no_koleo["auc"])
auc_with_koleo = np.array(results_with_koleo["auc"])
print("=" * 70)
print("AUC SCORES")
print("=" * 70)
print(f"Without KoLeo: {auc_no_koleo.mean():.4f} +/- {auc_no_koleo.std():.4f}")
print(f"With KoLeo: {auc_with_koleo.mean():.4f} +/- {auc_with_koleo.std():.4f}")
print("\n" + "=" * 70)
print("ELLIPSE AREAS")
print("=" * 70)
print(f"{'Class':<12} | {'Without KoLeo (mean +/- std)':<25} | {'With KoLeo (mean +/- std)':<25}")
print("-" * 70)
for cls in ["cat", "dog", "horse", "ship"]:
no_koleo_arr = np.array(results_no_koleo["areas"][cls])
with_koleo_arr = np.array(results_with_koleo["areas"][cls])
print(f"{cls:<12} | {no_koleo_arr.mean():.4f} +/- {no_koleo_arr.std():.4f} | {with_koleo_arr.mean():.4f} +/- {with_koleo_arr.std():.4f}")
print("\n" + "=" * 70)
print("Average area across all classes:")
all_no_koleo = np.array([np.mean(results_no_koleo["areas"][cls]) for cls in LABEL_NAMES])
all_with_koleo = np.array([np.mean(results_with_koleo["areas"][cls]) for cls in LABEL_NAMES])
print(f" Without KoLeo: {all_no_koleo.mean():.4f} +/- {all_no_koleo.std():.4f}")
print(f" With KoLeo: {all_with_koleo.mean():.4f} +/- {all_with_koleo.std():.4f}")
AUC SCORES
======================================================================
Without KoLeo: 0.9271 +/- 0.0040
With KoLeo: 0.9217 +/- 0.0036
======================================================================
ELLIPSE AREAS
======================================================================
Class | Without KoLeo (mean +/- std) | With KoLeo (mean +/- std)
----------------------------------------------------------------------
cat | 0.1567 +/- 0.0339 | 0.2162 +/- 0.0494
dog | 0.0781 +/- 0.0337 | 0.1458 +/- 0.0363
horse | 0.0618 +/- 0.0386 | 0.1436 +/- 0.0466
ship | 0.0486 +/- 0.0304 | 0.0819 +/- 0.0085
======================================================================
Average area across all classes:
Without KoLeo: 0.0844 +/- 0.0391
With KoLeo: 0.1432 +/- 0.0585
We can plot those data for better visualisation. The function is defined in plot_utils.py.
from plot_utils import plot_auc_and_ellipse_areas
plot_auc_and_ellipse_areas(
results_no_koleo,
results_with_koleo,
["Without KoLeo", "With KoLeo"],
LABEL_NAMES,
)
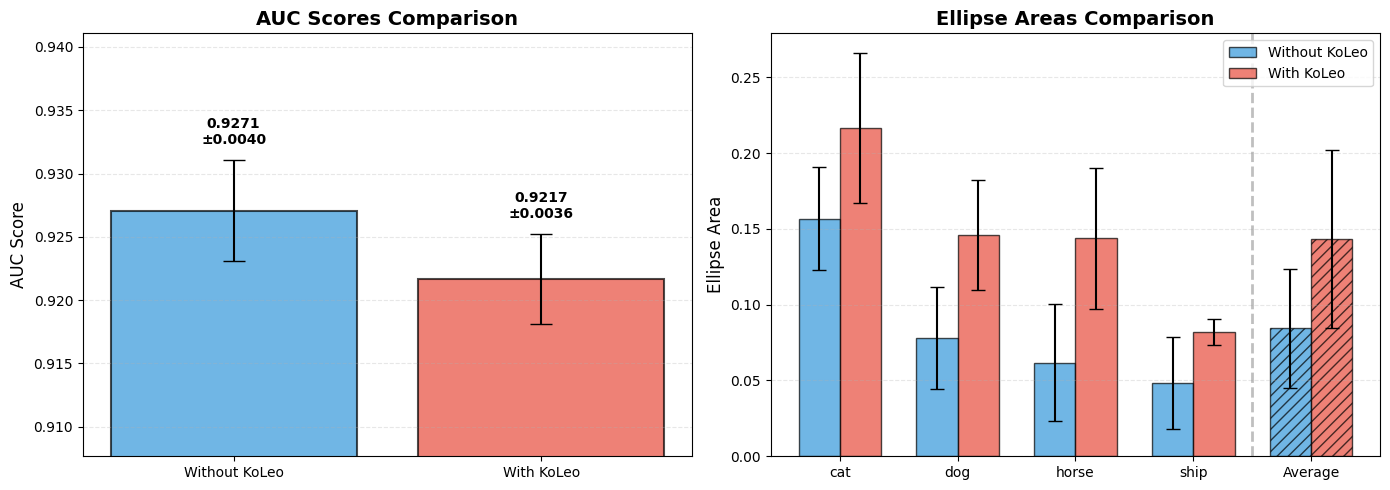
Cross-validation allows us to draw more robust conclusions about the effect of the KoLeo loss.
The AUC score, which measures the model’s ability to distinguish positive pairs from negative pairs, shows minimal impact.
The ellipse areas are systematically larger with the KoLeo loss across all classes, confirming that the regularization indeed spreads the embeddings in space.
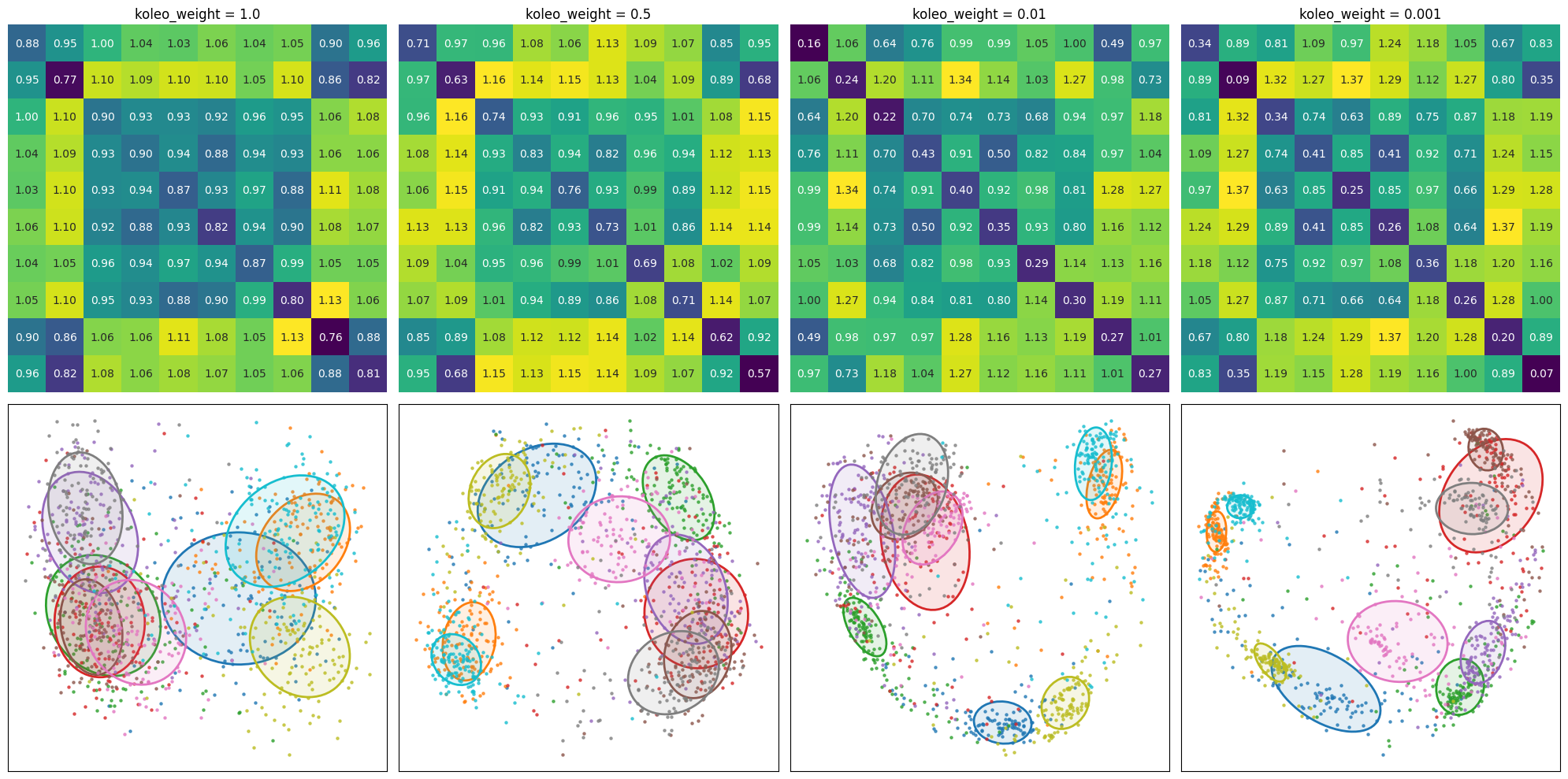
Effect of KoLeo loss weight
So far, we have compared training with and without the KoLeo loss. However, the weight \(\lambda\) in the total loss \(\mathcal{L} = \mathcal{L}_{triplet} + \lambda\mathcal{L}_{KoLeo}\) is a hyperparameter that controls the strength of the regularization. A larger \(\lambda\) should encourage a greater spread of embeddings, but may also affect the discrimination quality.
To understand this trade-off, we will train four models with different KoLeo loss weights: \(\lambda\) = 1.0, 0.5 (since we already done 0.1), 0.01, and 0.001. All models will be trained on the same train/validation split to ensure a fair comparison. Note that the goal here is not to find the best model, but rather to observe how the weight parameter affects the behavior of the embeddings. We defer this to a later time, where we will conduct a proper hyperparameter search.
Training
koleo_weights = [1.0, 0.5, 0.01, 0.001]
results = {}
epochs = 7
for koleo_weight in koleo_weights:
print(f"\n{'='*60}")
print(f"Training with koleo_weight = {koleo_weight}")
print(f"{'='*60}")
num_train = int((1 - val_split) * len(triplets))
np.random.seed(seed)
shuffle_indices = np.random.permutation(len(triplets))
shuffled_triplets = triplets[shuffle_indices]
shuffled_triplets_labels = triplets_labels[shuffle_indices]
train_triplets = shuffled_triplets[:num_train]
val_triplets = shuffled_triplets[num_train:]
val_labels = shuffled_triplets_labels[num_train:]
results[koleo_weight] = train_and_compute_metrics(train_triplets, val_triplets, val_labels, use_koleo=True, epochs=epochs)
print(f"Best AUC: {results[koleo_weight]['auc']:.4f}")
Results
For each training, we display the distance matrix and the PCA projection of the embeddings, then we will print a dataframe to compare the metrics we follow from the beginning of the study.
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
from matplotlib.patches import Ellipse
fig, axes = plt.subplots(2, 4, figsize=(20, 10))
for col_idx, kw in enumerate(koleo_weights):
data = results[kw]
ax_dist = axes[0, col_idx]
sns.heatmap(
data["dist_matrix"],
xticklabels=False,
yticklabels=False,
annot=True,
fmt='.2f',
cmap='viridis',
cbar=False,
ax=ax_dist
)
ax_dist.set_title(f'koleo_weight = {kw}', fontsize=12)
ax_dist.set_xticklabels(ax_dist.get_xticklabels(), rotation=45, ha='right')
ax_pca = axes[1, col_idx]
pca_df = pd.DataFrame({
'PC1': data["emb_2d"][:, 0],
'PC2': data["emb_2d"][:, 1],
'Label': data["lab_arr"]
})
palette = sns.color_palette("tab10", n_colors=10)
class_names = sorted(LABEL_NAMES)
color_map = {cls: palette[i] for i, cls in enumerate(class_names)}
for cls_idx, cls in enumerate(class_names):
mask = pca_df['Label'] == cls_idx
ax_pca.scatter(
pca_df.loc[mask, 'PC1'],
pca_df.loc[mask, 'PC2'],
c=[color_map[cls]],
alpha=0.7,
s=5,
label=None
)
ax_pca.set_xticks([])
ax_pca.set_yticks([])
ax_pca.set_xlabel('')
ax_pca.set_ylabel('')
ep = data["ellipse_params"][cls]
center, w, h, angle = ep["center"], ep["width"], ep["height"], ep["angle"]
color = color_map[cls]
ellipse = Ellipse(
xy=center, width=w, height=h, angle=angle,
facecolor=(*color, 0.12), edgecolor=color, linewidth=2
)
ax_pca.add_patch(ellipse)
plt.tight_layout()
plt.show()
metrics_data = []
for kw in koleo_weights:
data = results[kw]
avg_area = np.mean([data["areas"][cls] for cls in LABEL_NAMES])
metrics_data.append({
'koleo_weight': kw,
'AUC': data["auc"],
'Average Area': avg_area,
'cat': data["areas"]["cat"],
'dog': data["areas"]["dog"],
'horse': data["areas"]["horse"],
'ship': data["areas"]["ship"]
})
df_metrics = pd.DataFrame(metrics_data)
print(df_metrics.to_string(index=False))
| koleo_weight | AUC | Average Area | cat | dog | horse | ship |
|---|---|---|---|---|---|---|
| 1.000 | 0.782 | 0.303 | 0.273 | 0.160 | 0.224 | 0.269 |
| 0.500 | 0.885 | 0.193 | 0.309 | 0.159 | 0.203 | 0.122 |
| 0.010 | 0.932 | 0.130 | 0.324 | 0.119 | 0.194 | 0.067 |
| 0.001 | 0.928 | 0.110 | 0.306 | 0.039 | 0.101 | 0.026 |
Conclusion
In this chapter, we have explored the KoLeo loss as a regularization technique for Siamese networks. Through several experiments, we have gained insights into its behavior and effects.
Cross-validation results demonstrated that the KoLeo loss successfully achieves its primary objective: spreading embeddings in the representation space.
The effect of the weight parameter was further investigated by training models with different \(\lambda\) values (1.0, 0.5, 0.01, and 0.001). The results reveal a clear trade-off: as the KoLeo loss weight increases, the spread of embeddings (measured by ellipse areas) increases.
This trade-off highlights the importance of carefully choosing the weight parameter based on the specific requirements of the task. A larger weight may be beneficial when generalization and spread are priorities, while a smaller weight may be preferred when discrimination quality is critical.
The KoLeo loss has proven to be an effective regularization technique that can improve the distribution of embeddings in the representation space. However, as we noted, the loss is intrinsically dependent on batch size, which raises questions about the impact of gradient accumulation, a topic we will explore in the next chapter.
References
- Spreading Vectors for Similarity Search - Sablayrolles et al., ICLR 2019
- DINOv2: Learning Robust Visual Features without Supervision - Oquab et al., 2023