Blogs
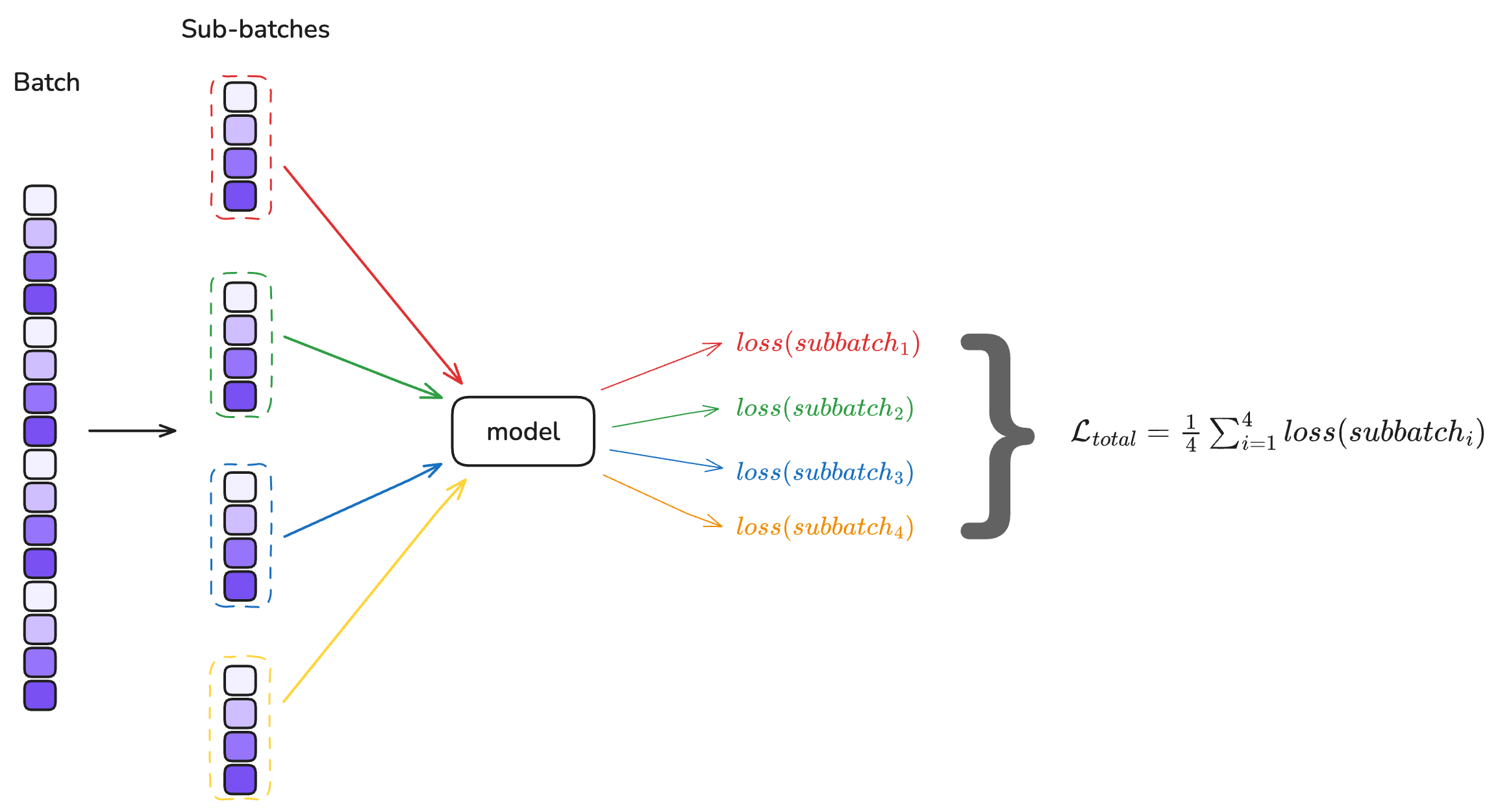
Gradient accumulation and …
In the previous chapter, we observed that the KoLeo loss successfully spreads embeddings in the representation space. However, we noted that the KoLeo loss is intrinsically dependent on batch size: it computes the minimum distance between each embedding and all other embeddings within the same …
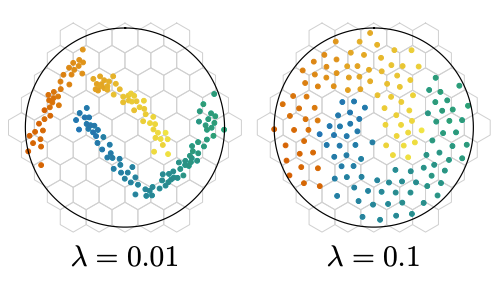
Effect of KoLeo loss on …
Introduction The KoLeo loss is a regularizer that pushes representations to spread uniformly in their space by maximizing their minimum distance from each other. It was introduced in this paper. It is a loss function derived from the Kozachenko–Leonenko estimator. It allows approximating Shannon …
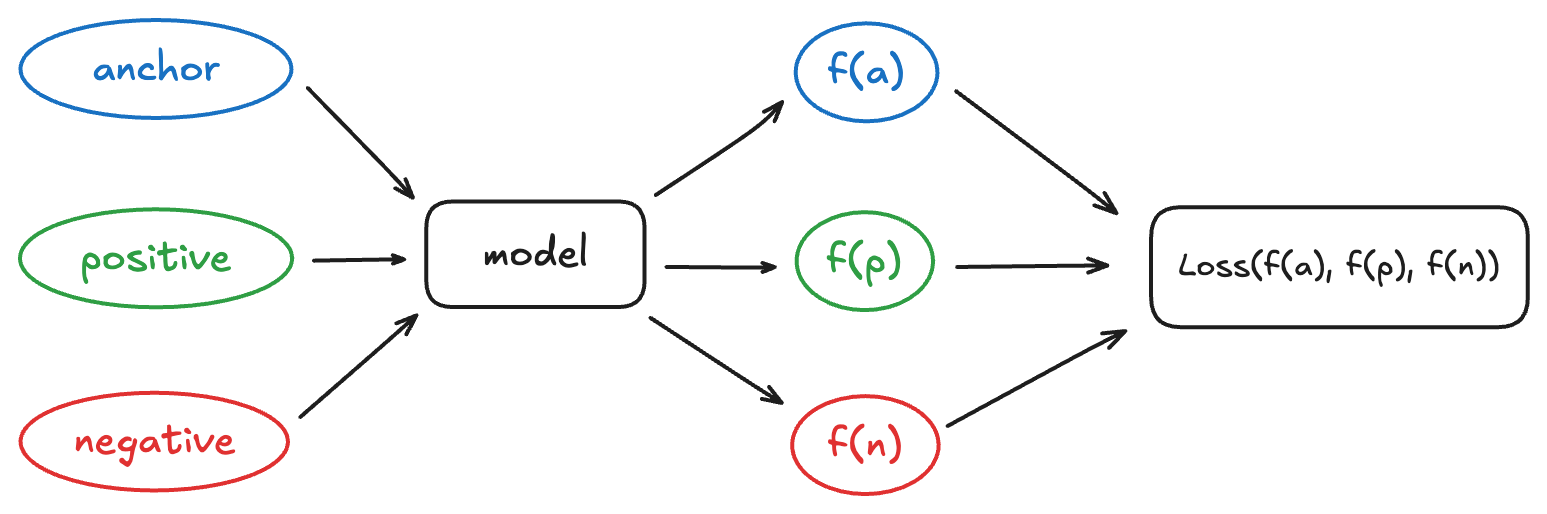
Training a siamese …
Introduction In computer vision, the most common goal is to classify an image (“cat”, “dog”, “car”, etc.). But in many cases, we are more interested in comparing images with each other: finding similar examples, grouping content, or measuring visual proximity. For this, we want to learn a …